Trong thực tế, kẻ tấn công thường lợi dụng các URL để tấn công người dùng. Các URL độc hại có thể được gửi tới người dùng thông qua email, tin nhắn văn bản, các cửa sổ pop-up trên trình duyệt web hoặc đính kèm thông tin quảng cáo điện tử. Khi người dùng vô tình truy vấn theo các URL độc hại, thì cũng là lúc tải về hệ thống của mình các phần mềm độc hại gây ra các nguy cơ về mất an toàn thông tin. Một trang web độc hại có thể làm lây nhiễm vài nghìn máy tính trong thời gian rất ngắn.
Vì vậy, việc nghiên cứu để phát hiện sớm có các kỹ thuật ngăn chặn URL độc hại trước khi người dùng truy vấn là biện pháp hiệu quả trong giải quyết vấn đề xâm nhập và phát tán các phần mềm độc hại thông qua môi trường web. Nhiệm vụ này được coi là một trong những hướng đi thu hút sự quan tâm của rất nhiều nhà nghiên cứu trong lĩnh vực bảo mật và an toàn thông tin, thực tế có một số kết quả khả quan được công bố.
Đôi nét về URL
Cấu trúc cơ bản của một liên kết URL gồm 3 phần chính: giao thức (protocol), tên miền (host name) và đường dẫn (path) như Hình 1.
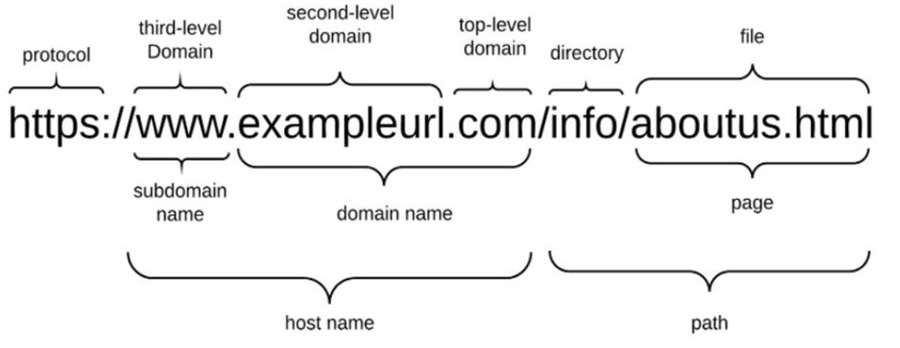
Hình 1. Cấu trúc cơ bản của URL
Rất nhiều lập luận cho rằng URL là một địa chỉ web nhưng thực tế nó không hoàn toàn đơn giản như vậy. Một địa chỉ web là URL nhưng tất cả URL không phải chỉ là địa chỉ web. Một số dịch vụ có thể truy cập trên Internet như FTP hoặc thậm chí MAILTO cũng được sử dụng dưới dạng URL. Phần Protocol của URL biểu thị giao thức mà ứng dụng và máy chủ giao tiếp. Phần Host name của URL có nhiệm vụ ánh xạ tới một địa chỉ IP của một tài nguyên trên Internet. Host name bao gồm các thành phần như tên miền phụ (Subdomain name), tên miền (Domain name) và tên miền cao cấp (Top-level domain). Ngoài ra, trong phần Host name có thể chứa thông tin người dùng (ví dụ //username:[email protected]) hoặc chứa thông tin về cổng kết nối dịch vụ (ví dụ //www.example.com:8080).
Nếu như phần Host name của URL đưa trình duyệt (hoặc các ứng dụng khác) đến đúng máy chủ trên mạng, thì phần Path sẽ giúp truy vấn đến đúng thư mục hoặc tệp tin trên máy chủ đó.
Ứng dụng trí tuệ nhân tạo trong việc phát hiện URL độc hại
Giải pháp hiện tại cho việc ngăn chặn các truy vấn URL độc hại đó là phương pháp sử dụng bộ lọc thực hiện so sánh với một danh sách Blacklist, bao gồm các tên miền, máy chủ lưu trữ và nội dung trang web độc hại đã biết. Tuy nhiên, phương pháp này tồn tại một vài điểm hạn chế như.
Thứ nhất, yêu cầu cập nhật Blacklist thường xuyên, liên tục, nếu không sẽ không thể phát hiện được những tên miền độc hại mới.
Thứ hai, phương pháp này chỉ có thể phát hiện ra các tên miền độc hại, kẻ tấn công hoàn toàn có thể khai thác các blacklist, thêm vào trong URL những đoạn code thực thi độc hại ẩn mình đằng sau các tên miền hợp lệ hoặc chuyển hướng các liên kết hợp lệ tới một trang web độc hại khác sau khi người dùng truy cập, khiến cho việc phát hiện ban đầu còn khó khăn hơn.
Trong những năm gần đây, công nghệ trí tuệ nhân tạo phát triển vô cùng mạnh mẽ, ứng dụng trong rất nhiều lĩnh vực khác nhau và đã gặt hái được những thành tựu đáng kể. Phát triển và ứng dụng công nghệ trí tuệ nhân tạo đang nhận được sự quan tâm đặc biệt của các nhà đầu tư, sự hỗ trợ mạnh mẽ của các cộng đồng phát triển với số lượng lớn các thư viện chức năng, đa dạng các nền tảng framework. Đặc biệt, các nhà khoa học không ngừng nghiên cứu phát triển các thuật toán mới, cải tạo cấu trúc mạng neuron, tối ưu hóa các thông số nhằm cải thiện hiệu năng huấn luyện trí tuệ nhân tạo.
Nhờ tính mở của Internet, mã nguồn mở dồi dào, phong phú cùng với sự hỗ trợ nhiệt tình từ cộng đồng, những nhà phát triển ứng dụng thường không gặp quá nhiều khó khăn để tự xây dựng cho mình một mô hình huấn luyện nhanh chóng và hiệu quả. Chính vì vậy, trong thời kỳ cách mạng công nghiệp 4.0 này, khi công nghệ trí tuệ nhân tạo đã phát triển đến một mức độ bão hòa thì chìa khóa thành công nằm ở công nghệ khai phá dữ liệu. Ai nắm trong tay dữ liệu phong phú và hoàn chỉnh thì mới có thể phát huy được hết sức mạnh của công nghệ trí tuệ nhân tạo và hướng tới thành công.
Một số nhà nghiên cứu trong lĩnh vực bảo mật và an toàn thông tin đã và đang nghiên cứu áp dụng trí tuệ nhân tạo để phát hiện sớm và ngăn chặn URL độc hại. Điển hình trong số đó phải kể đến các công trình nghiên cứu của Tiến sỹ Justin M. từ trường đại học UNIVERSITY OF CALIFORNIA [1]; Ethan M. Rudd, Richard Harang và Joshua Saxe từ Sophos Group [2]; nhóm tác giả Sungjin Kim a, Jinkook Kim b, Brent ByungHoon Kang đến từ trường đại học Korea Advanced Institute of Science and Technology (KAIST) và NCSOFT JAPAN K.K. [3,4]; hay tiến sỹ Steven C.H. Hoi từ School of Information Systems (SIS), Singapore Management University (SMU) [5,6] và tiến sỹ Daiki Chiba cùng nhóm tác giả đến từ NTT Secure Platform Laboratories, Tokyo, Japan [7]....
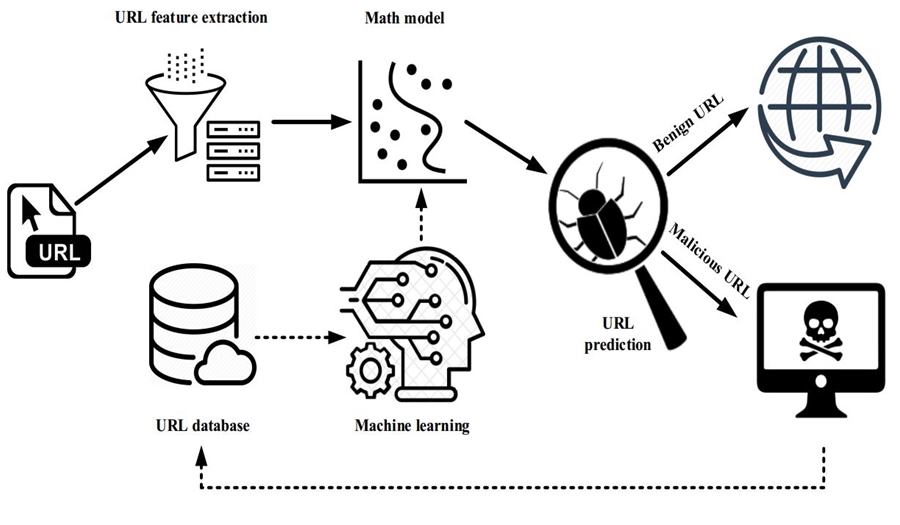
Hình 2. Quy trình sử dụng công nghệ trí tuệ nhân tạo phát hiện URL độc hại
Từ những kết quả nghiên cứu này đã chỉ ra rằng sử dụng trí tuệ nhân tạo để phân tích và phát hiện sớm những URL độc hại là một phương pháp hiệu quả hơn hẳn về mặt tốc độ xử lý và độ chính xác cao cùng với tính ổn định hơn so với phương pháp bộ lọc bằng blacklist truyền thống. Hình 2 mô tả quy trình áp dụng mạng neuron nhân tạo để phát hiện sớm URL độc hại.
Quy trình được thực hiện qua ba bước: Xây dựng và cập nhật cơ sở dữ liệu URL (URL database); Đào tạo, xây dựng mô hình dự đoán (Machine learning, Math Model); Và sử dụng mô hình dự đoán để phát hiện URL độc hại (URL prediction).
Trong đó, một trong những bước tiên quyết để quyết định sự thành công của phương pháp này là xây dựng và cập nhật cơ sở dữ liệu. Thông tin và các thuộc tính của các URL (URL feature) được lưu trữ chung trong cơ sở dữ liệu dưới dạng vector số. Cơ sở dữ liệu này được sử dụng trong mô hình huấn luyện một mạng neuron nhân tạo với đầu vào là các URL, đầu ra là kết quả đánh giá về tính độc hại của URL.
Kết quả của quá trình huấn luyện mạng neuron nhân tạo là thu được một mô hình toán học mô tả và lưu trữ thông tin cấu hình mạng neuron huấn luyện, giá trị tham số giữa các nốt mạng. Mô hình toán học này được truy xuất và sử dụng để đánh giá tính độc hại của các URL mới. Cơ sở dữ liệu liên tục được cập nhật trực tuyến và sử dụng cho tái huấn luyện mạng neuron nhân tạo để đảm bảo tính mới và độ chính xác của mô hình huấn luyện trí tuệ nhân tạo, cũng như sự hoạt động ổn định của hệ thống.
Ngoài một số yêu cầu cơ bản của một cơ sở dữ liệu là tính tự mô tả, tính độc lập, tính trừu tượng, tính nhất quán, tính toàn vẹn, thì cơ sở dữ liệu huấn luyện cần phải đạt được những yêu cầu khác như: Số lượng mẫu dữ liệu phải đủ lớn; Mẫu dữ liệu cần phải đa dạng, phân bố đều theo tỉ lệ số lượng; Dữ liệu cần phải sạch và được chuẩn hóa theo một tiêu chuẩn chung thuận lợi cho việc huấn luyện; Đối với mô hình huấn luyện có giám sát, mọi mẫu dữ liệu cần phải được gán nhãn một cách chính xác; Lựa chọn và trích xuất đặc trưng mẫu dữ liệu huấn luyện cần phải được tiến hành tỉ mỉ, khách quan.
Xây dựng cơ sở dữ liệu huấn luyện
Hiện nay có khá nhiều cơ sở dữ liệu về URL độc hại được công bố kèm theo kết quả nghiên cứu của các nhà nghiên cứu trong lĩnh vực an toàn thông tin hay các hãng công nghệ lớn. Tuy nhiên, các cơ sở dữ liệu này có số lượng mẫu khá khiêm tốn (chỉ từ vài chục, vài trăm nghìn mẫu). Ngoài ra, nhược điểm của các bộ cơ sở dữ liệu này còn là sự phân bố không đồng đều về số lượng giữa URL độc hại và không độc hại. Điều này dẫn tới vấn đề dữ liệu bất cân đối (Imbalance Data). Đây là vấn đề vẫn chưa được giải quyết triệt để trong lĩnh vực nghiên cứu ứng dụng và phát triển công nghệ trí tuệ nhân tạo. Không chỉ có vậy các cơ sở dữ liệu này còn khá cũ và không được cập nhật thường xuyên.
Như vậy, nhiệm vụ đầu tiên cần phải hoàn thành là tổng hợp những cơ sở dữ liệu sẵn có với độ tin cậy cao, thời gian cập nhật gần nhất, đồng thời bổ sung thêm từ các nguồn thu thập khác để đảm bảo tính mới, tính cân đối và đa dạng của cơ sở dữ liệu. Ngoài ra, các trang web khiêu dâm hoặc những trang web có nội dung độc hại không chỉ là môi trường thuận lợi để lây nhiễm và phát tán mã độc, mà những trang web này còn là nguyên nhân gây nên sự lệch lạc về văn hóa tư tưởng của một bộ phận người dùng, trong đó tập trung chủ yếu vào lứa tuổi trẻ vị thành niên dẫn đến tác động lớn trực tiếp và lâu dài tới đời sống con người, xã hội. Chính vì vậy, trong bộ cơ sở dữ liệu này ngoài những URL độc hại thông thường, những trang web có nội dung độc hại cũng cần phải được đưa vào và gắn nhãn URL nguy hiểm. Tiến hành tìm hiểu và phân tích các nguồn tài nguyên trên Internet để lựa chọn các nguồn tài nguyên có độ tin cậy cao, kết hợp tham khảo blacklist tổng hợp các tên miền độc hại do các hãng bảo mật nổi tiếng trên thế giới cung cấp, cơ sở dữ liệu lựa chọn thu thập và tổng hợp cơ sở dữ liệu từ các nguồn như Hình 3.
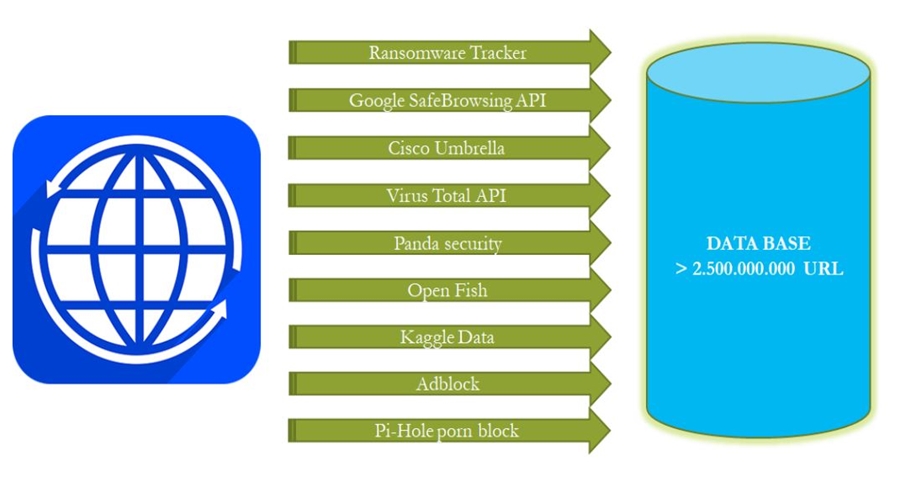
Hình 3. Tổng hợp các nguồn chính xây dựng cơ sở dữ liệu huấn luyện phân loại URL
Trong các nguồn dữ liệu, có một số nguồn cho phép tải dữ liệu trực tiếp dưới dạng file danh sách tổng hợp từ trước, một số nguồn cung cấp thông tin thông qua API của hãng và giới hạn số lượng 10.000 lượt truy vấn/ngày. Để phục vụ cho việc thu thập dữ liệu từ nhiều nguồn khác nhau, tác giả đã xây dựng một công cụ có tên URL_DataCrawler được viết bằng ngôn ngữ lập trình python, sử dụng luân phiên nhiều tài khoản khác nhau, thiết lập proxy khi cần thiết để khắc phục tình trạng hạn chế truy vấn thu thập thông tin từ một số nguồn như Google safe browsing API và Virus total API.
Tất cả các dữ liệu được thu thập về từ nhiều nguồn khác nhau cần thông qua một bước tiền xử lý, loại bỏ lỗi, lọc dữ liệu rác và chuẩn hóa kiểu dữ liệu theo một tiêu chuẩn chung thống nhất nhằm tạo điều kiện thuận lợi cho công tác phân tích.
Để dữ liệu có thể phục vụ tốt cho nhiều mô hình huấn luyện khác nhau (mô hình huấn luyện có giám sát và không có giám sát, mô hình huấn luyện sử dụng các thuật toán học máy thông thường hay mô hình huấn luyện sử dụng phương pháp học sâu), mỗi mẫu dữ liệu cần phải được gán nhãn một cách chính xác, đồng thời lựa chọn và trích xuất các đặc trưng tiêu biểu.
Những URL được xác nhận là độc hại (bao gồm 5 dạng chính: spam, phishing, malware, ransomware và darkweb) đều được gán nhãn tự động là 1, những URL an toàn được gán nhãn là 0 và lưu vào cơ sở dữ liệu. Trên cơ sở phân tích các kết quả nghiên cứu trước đó của các chuyên gia về lĩnh vực bảo mật và an toàn thông tin [8-11] đồng thời thông qua nghiên cứu chuyên sâu về cấu trúc của URL, các phương pháp tấn công lỗ hổng bảo mật ứng dụng web cùng các hành vi tấn công mạng thông qua URL, những tính chất sau được lựa chọn là đặc trưng tiêu biểu để phân định URL độc hại và an toàn:
1. Domain blacklist: Kiểm tra domain name của URL có nằm trong danh sách đen các tên miền độc hại hay không.
2. Google safe browsing: Kiểm tra tính an toàn của URL theo khuyến cáo của hãng Google thông qua Google safe browsing API.
3. Chỉ số Shannon Entropy: Chỉ số Shannon Entropy dùng để đánh giá tính ngẫu nhiên của chuỗi ký tự trong URL. Chỉ số này càng cao thì tính ngẫu nhiên của chuỗi ký tự càng lớn. Hệ số Shannon Entropy được tính theo công thức:
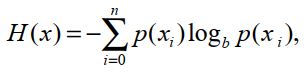
Trong đó: H(x) là chỉ số Shannon Entropy của chuỗi ký tự URL, p(xi) là hàm số tính khối lượng xác suất của mỗi ký tự trong chuỗi, b = 2.
4. Độ dài URL: Tổng số ký tự trong chuỗi ký tự của URL. Theo thống kê cho thấy chiều dài chuỗi ký tự của URL thường lớn hơn khá nhiều so với chiều dài của chuỗi ký tự của URL thông thường. Theo tiêu chuẩn SEO, URL đạt chuẩn cần phải ngắn gọn, rõ ràng, có cấu trúc dễ hiểu, dễ nhớ.
5. Túi đựng từ (Bag of words): Mô hình bag-of-words là một biểu diễn đơn giản hóa được sử dụng trong xử lý ngôn ngữ tự nhiên và truy xuất thông tin. Ý tưởng của mô hình Bag of words là phân tích và phân nhóm, đếm tần suất xuất hiện từ (ký tự) không phụ thuộc vào trật tự sắp xếp hay cú pháp. Mô hình Bag of words thường ứng dụng vào việc tìm kiếm, phân loại tài liệu, lọc spam xác định ý định của người dùng.
6. Tần suất xuất hiện của các ký tự đặc biệt: Đếm số lần xuất hiện của các ký tự đặc biệt trong chuỗi ký tự của URL.
7. Tần suất xuất hiện của ký tự số: Đếm số ký tự là chữ số xuất hiện trong chuỗi ký tự của URL.
Kết quả thống kê của các nghiên cứu đi trước cho thấy số lượng ký tự đặc biệt và ký tự số trong chuỗi ký tự của URL có sự chênh lệch khá lớn trong sự so sánh tương quan giữa các URL độc hại và các URL thông thường.
8. Sự xuất hiện của địa chỉ IP trong URL: Tìm kiếm và phát hiện sự xuất hiện của địa chỉ IP trong các URL.
9. Sự xuất hiện của các chuỗi ký tự nguy hiểm: Tìm kiếm và phát hiện sự xuất hiện của các chuỗi ký tự có ẩn chứa các tệp tin thực thi, các dấu hiệu hành vi khai thác thông tin như: .exe, .php, base64, /../, free, Free, FREE, .onion, .tor, .top, .bid, .ml, .bit, bitcoin, .php?email=, cmd=.
10. Tính thông dụng (tính mới) của URL: Kiểm tra domain name của URL theo danh sách top 1 triệu tên miền hợp lệ thông dụng do hãng Cisco Umbrella cung cấp. Để né tránh cách phòng thủ sử dụng các danh sách đen các miền để lọc và ngăn chặn các truy vấn độc hại, một chiến lược hiệu quả và được tin tặc sử dụng thường xuyên đó là sinh ra các tên miền ngẫu nhiên, hoàn toàn mới lạ. Những tên miền như thế được sinh liên tục, số lượng lớn có thể dễ dàng vượt qua phương pháp lọc truyền thống không có khả năng update blacklist theo thời gian thực.
Kết luận
Cơ sở dữ liệu được xây dựng tại phòng Lab nghiên cứu trí tuệ nhân tạo, Phòng Tự động hóa chỉ huy điều khiển thuộc Viện 10/BTL 86, sử dụng máy tính hiệu năng cao có cấu hình CPU Intel® Core™ i9-7900X 3.3 Ghz (20 cpus), 16Gb Ram DDR4, Video card Geforce RTX 2070 GDDR5 8Gb, SSD 512gb. Hệ thống chạy liên tục trong 896 giờ, kết quả thu được 2.688.430 mẫu dữ liệu với 29.572.730 thuộc tính (features) với tỉ lệ 50/50 Malicious-Benign URL. Dữ liệu xây dựng hoàn chỉnh sẽ được đưa vào để huấn luyện và kiểm tra kết quả huấn luyện trí tuệ nhân tạo, được sử dụng là công nghệ lõi để phát triển hệ thống tự động phát hiện sớm truy vấn độc hại. Nên đây là cơ sở để chuẩn bị cho việc xây dựng phương pháp sử dụng công nghệ trí tuệ nhân tạo để phát hiện URL độc hại.
|
TÀI LIỆU THAM KHẢO 1. Justin Ma. Learning to Detect Malicious URLs. dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy. University of California, SAN DIEGO, 2010, 144p. 2. Ethan M. Rudd, Richard Harang, and Joshua Saxe. MEADE: Towards a Malicious Email Attachment Detection Engine. In Conference: 2018 IEEE International Symposium on Technologies for Homeland Security (HST), DOI: 10.1109/THS.2018.8574202. 3. Sungjin Kim, Jinkook Kim, Seokwoo Nam, Jonghyun Jin, Dohoon Kim, WebMon: ML- and YARA-based Malicious Webpage Detection, Computer Networks (2018), doi: 10.1016/j.comnet.2018.03.006. 4. Sungjin Kim, Jinkook Kim, Brent Byung, Hoon Kang. Malicious URL protection based on attackers’ habitual behavioral analysis. Computers & Security Volume 77, August 2018, Pages 790-806. DOI 10.1016/j.cose.2018.01.013 5. Hyunsang Choi, Bin Zhu, Heejo Lee. Detecting Malicious Web Links and Identifying Their Attack Types. In USENIX Conference on Web Application Development, 2011. 6. Sahoo D., Liu C.and Hoi, S. C. Malicious URL Detection using Machine Learning: A Survey. arXiv preprint arXiv:1701.07179., pages 1–21,2017. 7. Daiki Chiba, Mitsuaki Akiyama, Takeshi Yagi, Kunio Hato, Tatsuya Mori, Shigeki Goto, DomainChroma: Building Actionable Threat Intelligence from Malicious Domain Names, Computers & Security (2018), doi: 10.1016/j.cose.2018.03.013. 8. Dharmaraj R. Patil, J. B. Patil. Malicious URLs Detection Using Decision Tree Classifiers and Majority Voting Technique. In Cybernetics and information technologies, Volume 18, No 1, Print ISSN: 1311-9702; Online ISSN: 1314-4081, pp. 11-29. 9. Kaspersky Enterprise Cybersecurity, Machine Learning for Malware Detection, 2017 AO Kaspersky Lab. 10. Alibaba Cloud. Machine Learning-based Web Exception Detection. //medium.com /@Alibaba_Cloud/machine-learning-based-web-exception-detection-af49eaf5994. 11. Verma R., A. Das. What’s in a URL: Fast Feature Extraction and Malicious URL Detection. In: Proc. of 3rd International Workshop on Security and Privacy Analytics, 2017, pp. 55-63. |
TS. Hoàng Văn Chí

08:00 | 27/11/2019
08:00 | 27/03/2019

09:00 | 08/01/2018

16:00 | 04/08/2024
Với sự phát triển mạnh mẽ của công nghệ số, số lượng các phần mềm chương trình được công bố ngày càng lớn. Song hành với đó là việc tin tặc luôn tìm cách phân tích, dịch ngược các chương trình nhằm lấy cắp ý tưởng, bẻ khóa phần mềm thương mại gây tổn hại tới các tổ chức, cá nhân phát triển phần mềm. Đặc biệt, trong ngành Cơ yếu có những chương trình có tích hợp các thuật toán mật mã ở mức mật và tối mật thì việc chống phân tích, dịch ngược có vai trò hết sức quan trọng. Do đó, việc phát triển một giải pháp bảo vệ các chương trình phần mềm chống lại nguy cơ phân tích, dịch ngược là rất cấp thiết.

09:00 | 18/07/2024
Mới đây, Bộ Công an đã thông tin về tình trạng tin nhắn tin nhắn thương hiệu (SMS Brandname) giả mạo phần lớn xuất phát từ việc các đối tượng sử dụng trạm phát sóng BTS giả mạo để gửi hàng loạt tin nhắn lừa đảo tới người dùng với mục đích nhằm chiếm đoạt tài sản.

08:00 | 22/05/2024
Phần II của bài báo tiếp tục tập trung đánh giá một số công nghệ Blockchain phổ biến hiện nay, từ đó, xem xét tính ứng dụng của các công nghệ này đối với Việt Nam.

14:00 | 04/03/2024
Ngày nay, tất cả các lĩnh vực trong đời sống xã hội đều có xu hướng tích hợp và tự động hóa, trong đó các giao dịch số là yêu cầu bắt buộc. Do vậy, các tấn công lên thiết bị phần cứng, đặc biệt là các thiết bị bảo mật có thể kéo theo những tổn thất to lớn như: lộ thông tin cá nhân, bị truy cập trái phép hoặc đánh cắp tài khoản ngân hàng,… So với các loại tấn công khác, tấn công kênh kề hiện đang có nhiều khả năng vượt trội. Trong bài báo này, nhóm tác giả sẽ trình bày sơ lược về kết quả thực hành tấn công kênh kề lên mã khối Kalyna trên hệ thống Analyzr của Viện Khoa học - Công nghệ mật mã. Nhóm tác giả đã tấn công thành công và khôi phục đúng 15 byte khóa trên tổng số 16 byte khóa của thuật toán Kalyna cài đặt trên bo mạch Nucleo 64.

14:00 | 11/09/2024|Công nghệ PKI

11:00 | 03/09/2024|GP ATM

08:00 | 26/08/2024|GP ATM

10:00 | 19/08/2024|Tin tức sản phẩm
Trong thời đại ngày nay, cùng với sự phát triển của khoa học kỹ thuật có ngày càng nhiều những cuộc tấn công vào phần cứng và gây ra nhiều hậu quả nghiêm trọng. So với các loại tấn công khác, tấn công qua kênh kề đang được nghiên cứu do khả năng khôi phục lại khóa bí mật trong khi hệ thống vẫn hoạt động bình thường mà không hề làm thay đổi phần cứng. Bài báo này sẽ trình bày một cách sơ lược về những kết quả cuộc tấn công kênh kề lên mã hóa RSA cài đặt trên điện thoại thông minh sử dụng hệ điều hành Android tại Viện Khoa học - Công nghệ mật mã. Nhóm tác giả đã tấn công khôi phục được một phần khóa bí mật của mã hóa RSA cài đặt trên điện thoại thông minh và chứng minh khả năng rò rỉ thông tin qua kênh kề.
14:00 | 11/09/2024

Một ví dụ điển hình trong việc triển khai mô hình Zero Trust thành công là của Tập đoàn công nghệ Microsoft. Điều này minh chứng cho cách một tổ chức lớn có thể bảo vệ tài nguyên và người dùng bằng các phương pháp kiểm soát nghiêm ngặt, đảm bảo an ninh mạng toàn diện. Đây cũng là bài học kinh nghiệm cho các tổ chức trong quá trình triển khai mô hình bảo mật hiện đại này.
10:00 | 14/11/2024