Các khái niệm cơ bản
Trong thống kê, mọi phỏng đoán liên quan đến phân phối chưa biết F của một biến ngẫu nhiên X được gọi là giả thiết thống kê. Ở một giả thiết cụ thể, nếu mục đích của tiêu chuẩn thống kê là xác minh xem liệu giả thiết này có sai hay không mà không tiến hành điều tra các giả thiết khác, thì tiêu chuẩn như vậy được gọi là tiêu chuẩn ý nghĩa. Một giả thiết thống kê chỉ đề cập đến giá trị số của các tham số chưa biết của một phân bố được gọi là giả thiết tham số. Phương pháp để xác minh giả thiết thống kê được gọi là kiểm định thống kê. Kiểm định của các giả thiết tham số được gọi là kiểm định tham số. Cũng có thể có các giả thiết không tham số và các kiểm định không tham số.
Như vậy, giả thiết duy nhất cần được chỉ rõ trong kiểm định này và thể hiện sự kiện chống lại được gọi là giả thiết null. Một kết quả được cho là có ý nghĩa thống kê nếu nó cho phép bác bỏ giả thiết null (“null” có liên quan tới động từ “nullify-bác bỏ”). Theo lập luận bác bỏ một luận đề (reductio ad adsurdum reasoning), kết quả có ý nghĩa thống kê sẽ rất khó khả thi nếu giả thiết null được cho là đúng. Việc bác bỏ giả thiết null ngụ ý rằng, giả thiết chuẩn xác (đối thiết - alternative hypothesis) nằm trong phần bổ sung logic của giả thiết null. Tuy nhiên, việc bác bỏ giả thiết null không cho biết cái nào trong số các đối thiết sẽ là đúng, trừ khi có một đối thiết đơn cho giả thiết null.
Ví dụ, nếu một giả thiết null nói rằng, một thống kê giản lược nào đó tuân theo phân bố chuẩn N(0,1) thì việc bác bỏ giả thiết null này có thể có nghĩa là (i) giá trị trung bình không bằng 0, hoặc (ii) phương sai không phải là 1 hoặc (iii) phân bố không là chuẩn tắc và phụ thuộc vào loại kiểu của kiểm định được thực hiện. Tuy nhiên, trong trường hợp cùng đạt được bác bỏ giả thiết trung bình bằng 0 và biết được phân bố là chuẩn tắc, phương sai bằng 1 thì phép kiểm định giả thiết null cũng không cho biết giá trị khác 0 nào mà chỉ có thể chấp nhận nó là trung bình chuẩn xác.
p-giá trị được sử dụng trong bối cảnh kiểm định giả thiết null để định lượng khái niệm về ý nghĩa thống kê của bằng chứng. Kiểm định giả thiết null là lập luận bác bỏ một luận đề được thích nghi cho khoa học thống kê. Về bản chất, một khẳng định được coi là hợp lệ nếu khẳng định đối lập của nó không thể thực hiện được.
Nếu X là một biến ngẫu nhiên biểu diễn dữ liệu được quan sát và H là giả thiết thống kê đang được xem xét, thì khái niệm về ý nghĩa thống kê có thể được định lượng một cách đơn giản bởi xác suất có điều kiện Pr(X|H), đưa ra khả năng của một sự kiện quan sát nhất định X nếu giả thiết H được cho là đúng. Tuy nhiên, nếu X là một biến ngẫu nhiên liên tục, xác suất quan sát được một trường hợp cụ thể của x là bằng 0. Nghĩa là, Pr(X = x|H) = 0. Do đó, định nghĩa đơn giản này là không đủ và cần phải thay đổi để phù hợp với các biến ngẫu nhiên liên tục.
Điều này giúp làm rõ rằng các p-giá trị không nên bị nhầm lẫn với xác suất về giả thiết (như được thực hiện trong kiểm định giả thiết Bayes) chẳng hạn như: Pr(H|X) - xác suất của giả thiết khi dữ liệu đã được cho, hoặc Pr(H) - xác suất của giả thiết là đúng, hoặc Pr(X) - xác suất của việc quan sát được dữ liệu đã cho.
Định nghĩa p-giá trị
p-giá trị được định nghĩa là xác suất, dưới giả thiết null H (đôi khi được ký hiệu là H0 trái ngược với Ha biểu thị giả thiết thay thế (alternative), null còn có nghĩa là “0”) về phân phối chưa biết F của biến ngẫu nhiên X, cho biến được quan sát như là một giá trị bằng hoặc thái cực (extreme) hơn giá trị quan sát được (có thể là “lớn hơn” hay “nhỏ hơn”). Nếu x là giá trị quan sát được, thì tùy thuộc vào cách mà chúng ta diễn giải nó. Quan điểm bằng hoặc thái cực hơn so với cái mà thực tế đã quan sát được có thể ngụ ý rằng {X ≥ x} (sự kiện đuôi bên phải), {X ≤ x} (sự kiện đuôi bên trái) hoặc sự kiện đưa ra xác suất nhỏ nhất trong số {X ≤ x} và {X ≥x} (sự kiện có hai đuôi).
Tức là, p-giá trị được cho bởi 3 giá trị: Pr(X ≥ x|H) cho sự kiện đuôi bên phải; Pr(X ≤ x|H) cho sự kiện đuôi bên trái và 2.min{Pr(X ≤ x|H), Pr(X ≥ x|H)} cho sự kiện có hai đuôi.
Có một vài cách biểu diễn p-giá trị như: p-value theo Hiệp hội Thống kê Hoa Kỳ; P value theo Hiệp hội Y học Hoa Kỳ còn theo Hiệp hội Tâm lý Hoa Kỳ thì nó được ký hiệu là p value.
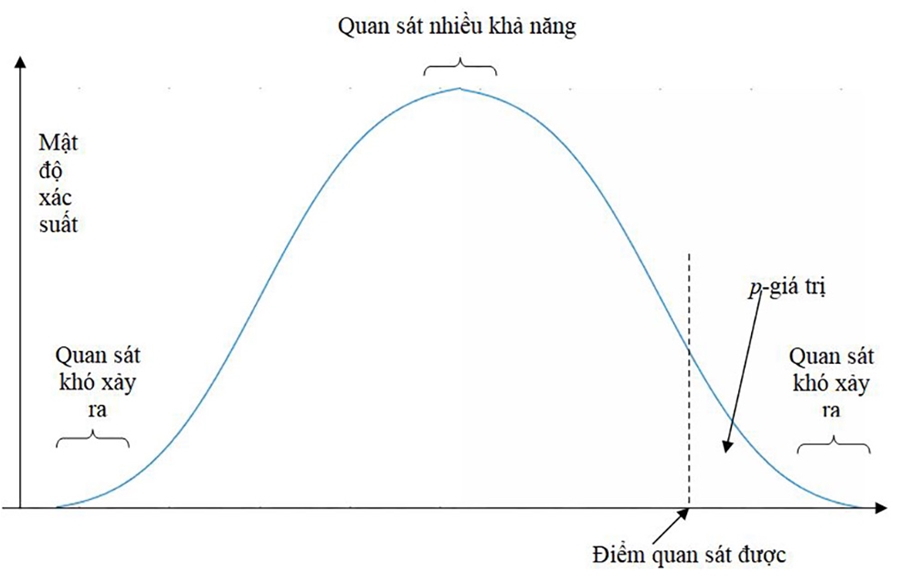
Hình 1. Ví dụ của việc tính p-giá trị
Hình 1 mô tả một ví dụ về việc tính p-giá trị. Trong đó, trục tung là mật độ xác suất của mỗi kết quả, được tính dưới giả thiết null. p-giá trị là diện tích được giới hạn bởi đường thẳng đứng đi qua điểm quan sát được và phía dưới đường mật độ xác suất. Đó là xác suất của kết quả quan sát được (hoặc thái cực hơn) với giả thiết rằng giả thiết null đúng.
p-giá trị càng nhỏ thì ý nghĩa càng cao bởi, nó giúp người điều tra nhận biết, giả thiết đang được xem xét có thể không giải thích thỏa đáng quan sát. Giả thiết null H bị bác bỏ nếu một trong ba xác suất trên nhỏ hơn hoặc bằng một giá trị ngưỡng nhỏ, cố định nhưng được xác định trước một cách tùy ý α, được gọi là mức ý nghĩa. Không giống như p-giá trị, mức α không xuất phát từ bất kỳ dữ liệu quan sát nào và không phụ thuộc vào giả thiết nằm ở cơ sở. Thay vào đó, giá trị của α được đặt ra bởi nhà nghiên cứu trước khi kiểm tra dữ liệu, nên giá trị của α là tùy ý. Theo quy ước, α thường được đặt bằng 0,05; 0,01; 0,005 hoặc 0,001.
Vì giá trị của x xác định sự kiện đuôi bên trái hoặc đuôi bên phải là một biến ngẫu nhiên, nên p-giá trị trở thành một hàm của x và nó là một biến ngẫu nhiên. Dưới giả thiết null, p-giá trị được xác định đều trên khoảng [0, 1], giả sử rằng x là liên tục. Do đó, p-giá trị không cố định.
Ví dụ, một thí nghiệm được thực hiện để xác định xem kết quả của việc tung đồng xu có cân bằng hay không (cơ hội bằng nhau của việc hạ cánh sấp (tails) hay ngửa (heads) hoặc có lệch không cân bằng (một kết quả có nhiều khả năng hơn so với kết quả khác).
Giả sử, các kết quả thí nghiệm cho thấy đồng xu quay mặt ngửa lên trên 14 lần trong tổng số 20 lần tung. Giả thiết null là đồng xu là cân bằng và thống kê kiểm định là số lần rơi mặt ngửa. Nếu kiểm định đuôi bên phải được xem xét, p-giá trị của kết quả này là cơ hội để một đồng xu cân bằng rơi trên mặt ngửa ít nhất 14 lần trong số 20 lần tung. Xác suất đó có thể được tính từ các hệ số nhị thức là:
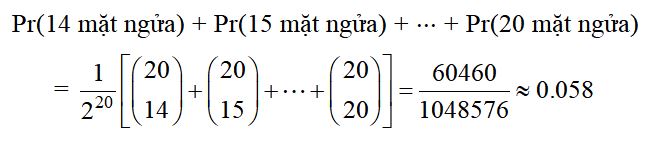
Xác suất này là p-giá trị, chỉ xem xét các kết quả cực đoan mà có lợi cho mặt ngửa. Đây được gọi là thí nghiệm một đuôi (bên phải). Tuy nhiên, thiên lệch có thể theo một trong hai hướng, thiên về các mặt ngửa hoặc các mặt sấp. Thay vào đó có thể tính p-giá trị hai phía, xem xét thiên lệch nghiêng về các mặt ngửa hoặc các mặt sấp. Vì phân phối nhị thức là đối xứng cho một đồng tiền cân bằng, p-giá trị hai phía chỉ đơn giản là gấp đôi p-giá trị một phía đã tính được tính, cho kết quả p-giá trị 0,116.
Phân tích cụ thể ví dụ trên, ta có:
- Giả thiết null (H0): đồng tiền là cân bằng với Pr (rơi với mặt ngửa) = 0,5.
- Thống kê kiểm định: Số lần rơi với mặt ngửa.
- Mức: 0,05.
- Quan sát O: 14 lần mặt ngửa trong số 20 lần tung.
- p-giá trị hai phía của quan sát O khi có H0 = 2.min{Pr(số mặt ngửa ≥14), Pr (số mặt ngửa ≤14)} = 2.min{0,058, 0,978} = 0,116.
Lưu ý, Pr(số mặt ngửa ≤ 14 đầu) = 1 - Pr(số mặt ngửa ≥ 14) + Pr(số mặt ngửa = 14) = 1 – 0,058 + 0,036 = 0,978. Tuy nhiên, tính đối xứng của phân bố nhị thức nên phải tính để thực hiện tìm xác suất nhỏ hơn trong hai xác suất. Ở đây, p-giá trị được tính vượt quá 0,05, có nghĩa là dữ liệu nằm trong phạm vi của những gì sẽ xảy ra 95% số lần nếu đồng tiền trong thực tế cân bằng. Do đó, giả thiết null không bị bác bỏ ở mức 0,05.
Tuy nhiên, nếu có thêm một mặt ngửa nữa, p-giá trị kết quả (hai phía) sẽ là 0,0414 (4,14%). Trong trường hợp đó, giả thiết null sẽ bị từ chối ở mức 0,05.
Lịch sử ra đời
Việc tính toán các p-giá trị có từ những năm 1700. Khi đó, chúng được ứng dụng cho bài toán tỷ lệ giới tính con người khi sinh và ý nghĩa thống kê so với giả thiết null về xác suất sinh con trai và gái bằng nhau. Năm 1710, John Arbuthnot - người nghiên cứu câu hỏi này đã kiểm tra hồ sơ sinh tại London trong 82 năm (từ 1629 đến 1710). Mỗi năm, số nam giới sinh ra ở London đều vượt quá số nữ. Khi xem số lần sinh con trai nhiều hơn hay số lần sinh con gái nhiều hơn có khả năng như nhau, thì xác suất của kết quả quan sát được là 0,582, hoặc khoảng 1 trong 4.836.000.000.000.000.000.000.000 trường hợp. Trong thuật ngữ hiện đại, đó chính là p-giá trị. Giá trị này nhỏ đến đáng kinh ngạc, khiến Arbuthnot đi đến kết luận rằng, đây là điều không thể tính toán được mà do tự nhiên. Theo thuật ngữ hiện đại, ông bác bỏ giả thiết null về khả năng sinh con trai và con gái có khả năng như nhau ở mức ý nghĩa p = 1/282.

Hình 2. John Arbuthnot
Câu hỏi tương tự sau đó đã được giải quyết bởi Pierre-Simon Laplace, người đã sử dụng một kiểm định có tham số khi mô hình hóa số ca sinh con trai với phân phối nhị thức. Vào những năm 1770, Laplace đã xem xét số liệu thống kê của gần nửa triệu ca sinh. Các số liệu thống kê cho thấy sự dư thừa của các chàng trai so với các cô gái. Ông kết luận, bằng cách tính p-giá trị phần vượt quá là hiệu ứng thực, nhưng vẫn chưa đưa ra được lời giải thích thỏa đáng.

Hình 3. Pierre-Simon Laplace
p-giá trị lần đầu tiên được giới thiệu chính thức bởi Karl Pearson, trong kiểm định chi-bình phương Pearson của ông, bằng cách sử dụng phân bố chi-bình phương và ký hiệu là P viết hoa. Các p-giá trị cho phân bố chi-bình phương (cho các giá trị khác nhau của χ2 và các bậc tự do), hiện được ký hiệu là P đã được tính trong [2] của Elderton và được thu thập trong [3].

Hình 4. Karl Pearson
Việc sử dụng p-giá trị trong thống kê đã được phổ biến bởi Ronald Fisher và nó đóng vai trò trung tâm trong cách tiếp cận của ông đối với chủ đề này. Trong cuốn sách có ảnh hưởng lớn Statistical methods for research workers (1925), Fisher đã đề xuất mức p = 0,05 hoặc khả năng vượt quá 1 trong 20, do tình cờ, như là một giới hạn cho ý nghĩa thống kê và áp dụng điều này cho phân bố chuẩn tắc (như một kiểm định hai phía).
Sau đó, ông đã tính toán một bảng các giá trị tương tự như Elderto. Tuy nhiên, ông đảo ngược vai trò của χ2 và p. Nghĩa là, thay vì tính p cho các giá trị khác nhau của χ2 (và bậc tự do n), ông đã tính các giá trị của χ2 mà mang lại các p-giá trị được chỉ định, cụ thể: 0,99; 0,98; 0,95; 0,90; 0,80; 0,70; 0,50; 0,30; 0,20; 0,10; 0,05; 0,02 và 0,01. Điều đó cho phép so sánh các giá trị tính được của χ2 so với ngưỡng và khuyến khích sử dụng các p-giá trị (đặc biệt là 0,05; 0,02 và 0,01) làm điểm cắt.

Hình 5. Ronald Fisher
Như một minh họa về việc áp dụng các p-giá trị vào mục đích và giải thích các thí nghiệm, trong cuốn sách The Design of Experiment (1935), Fisher đã trình bày thí nghiệm nếm trà của một phụ nữ tên là Muriel Bristol. Đây là ví dụ điển hình của p-giá trị. Để đánh giá tuyên bố, Muriel Bristol có thể phân biệt cách pha trà bằng cách nếm (cho sữa vào cốc trước, rồi sau đó mới cho trà, hoặc ngược lại). Muriel Bristol được đưa cho 8 cốc trà pha theo hai cách trên với tỉ lệ như nhau và được yêu cầu xác định cách pha trà mỗi cốc. Trong trường hợp giả thiết null là cô ấy không có khả năng đặc biệt, kiểm định là kiểm định chính xác của Fisher và p-giá trị là:
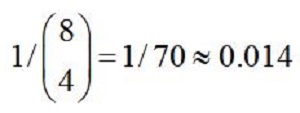
Fisher sẵn sàng từ chối giả thiết null (xem xét kết quả rất khó xảy ra do tình cờ) nếu tất cả các cốc được phân loại một cách chính xác. Trong thí nghiệm thực tế, Bristol đã phân loại chính xác tất cả 8 cốc.
Fisher nhắc lại ngưỡng p = 0,05 và giải thích tính hợp lý rằng, thông thường, để thuận tiện, các nhà thí nghiệm lấy 5% làm mức ý nghĩa tiêu chuẩn, theo đó, họ sẵn sàng bỏ qua tất cả các kết quả mà không đạt được tiêu chuẩn này. Bằng cách này, họ loại khỏi cuộc thảo luận tiếp theo phần lớn hơn của những biến động mà các nguyên nhân tình cờ đã đưa vào các kết quả thí nghiệm.
Phân bố và cách tính
Khi giả thiết null là đúng, nếu nó có dạng H0: ϴ=ϴ0 (kiểm định tham số) và biến ngẫu nhiên nằm ở cơ sở là liên tục, thì phân phối xác suất của p-giá trị là đều trên khoảng [0,1]. Ngược lại, nếu giả thiết thay thế (đối thiết) là đúng, phân bố phụ thuộc vào kích thước mẫu và giá trị thực của tham số đang được nghiên cứu [4,5].
Thông thường, X là một thống kê kiểm định, thay vì bất kỳ quan sát nào trong số các quan sát thực tế. Thống kê kiểm định là đầu ra của một hàm vô hướng của tất cả các quan sát. Thống kê này cung cấp một số duy nhất, chẳng hạn như trung bình hoặc hệ số tương quan, tóm tắt các đặc điểm của dữ liệu theo cách có liên quan đến một cuộc điều tra cụ thể. Như vậy, thống kê kiểm định tuân theo một phân bố được xác định bởi hàm, được sử dụng để xác định con số thống kê của kiểm định đó và phân bố của dữ liệu quan sát đầu vào.
Đối với trường hợp quan trọng trong đó dữ liệu được giả định tuân theo phân bố chuẩn tắc, tùy thuộc vào bản chất của thống kê kiểm định mà giả thiết cơ sở của thống kê kiểm định, các cách kiểm định giả thiết null khác nhau đã được phát triển. Một số bài kiểm định như vậy là z-kiểm định cho phân bố chuẩn tắc, t-kiểm định cho t-phân bố của Student, f-kiểm định cho f-phân bố. Khi dữ liệu không tuân theo phân bố chuẩn tắc, vẫn có thể xấp xỉ phân bố của các thống kê kiểm định này qua phân bố chuẩn tắc bằng cách gọi định lý giới hạn trung tâm cho các mẫu lớn, như trong trường hợp kiểm định chi-bình phương của Pearson.
Việc tính toán p-giá trị đòi hỏi một giả thiết null, thống kê kiểm định (cùng với việc quyết định liệu nhà nghiên cứu đang thực hiện kiểm định một phía hay hai phía) và dữ liệu. Mặc dù điều này có thể dễ dàng nhưng việc tính phân bố lấy mẫu theo giả thiết null và sau đó việc tính hàm phân bố tích lũy thường là một vấn đề khó khăn. Ngày nay, việc tính toán này được thực hiện bằng phần mềm thống kê thông qua các phương pháp tính số (chứ không phải là công thức chính xác). Thực tế, vào nửa đầu thế kỷ XX, điều này đã được thực hiện thông qua các bảng giá trị và người ta đã ngoại suy hoặc nội suy ra các p-giá trị từ các giá trị rời rạc này. Thay vì sử dụng một bảng của các p-giá trị, Fisher đã tính ngược các hàm phân bố tích lũy, công bố một danh sách các giá trị của thống kê kiểm định cho các p-giá trị cố định cho trước. Điều này tương ứng với việc tính hàm phân vị (hàm phân bố tích lũy nghịch đảo với các khoảng chia bằng nhau).
Sử dụng
p-giá trị được sử dụng rộng rãi trong kiểm định giả thiết thống kê, đặc biệt trong kiểm định ý nghĩa của giả thiết null. Trong phương pháp này, nó là một phần của mục đích thí nghiệm. Trước khi thực hiện thí nghiệm, người ta chọn một mô hình (giả thiết null) và giá trị ngưỡng cho p, được gọi là mức ý nghĩa của kiểm định, theo truyền thống là 5% hoặc 1% và được ký hiệu là α. Nếu p-giá trị nhỏ hơn mức ý nghĩa đã chọn (α), điều đó cho thấy, dữ liệu được quan sát không phù hợp một cách thích đáng với giả thiết null và giả thiết null có thể bị bác bỏ. Tuy nhiên, trong trường hợp ngược lại, điều đó không chứng minh rằng giả thiết được kiểm định là đúng. Khi p-giá trị được tính toán chính xác, kiểm định này đảm bảo rằng tỷ lệ lỗi loại I nhiều nhất là α. Đối với phân tích điển hình, sử dụng ngưỡng cắt α = 0,05 tiêu chuẩn, giả thiết null bị từ chối khi p < 0,05 và không bị từ chối khi p > 0,05. Bản thân p-giá trị tự nó không hỗ trợ lý luận về các xác suất của các giả thiết mà chỉ là một công cụ để quyết định có từ chối giả thiết null hay không.
Một số sai lầm thường gặp
Sử dụng sai các p-giá trị hoặc giải thích sai về p-giá trị khá phổ biến trong nghiên cứu khoa học và đào tạo khoa học.
Từ cách tiếp cận kiểm định giả thiết Neyman-Pearson cho các suy luận thống kê, dữ liệu thu được bằng cách so sánh p-giá trị với mức ý nghĩa sẽ mang lại một trong hai kết quả: giả thiết null bị từ chối (tuy nhiên không chứng minh rằng giả thiết null là sai) hoặc giả thiết null không thể bị bác bỏ ở mức ý nghĩa đó (tuy nhiên điều đó không chứng minh rằng giả thiết null là đúng).
Từ cách tiếp cận kiểm định thống kê của Fisher cho các suy luận thống kê, một p-giá trị thấp có nghĩa là: giả thiết null là đúng và một sự kiện rất khó có khả năng đã xảy ra hoặc giả thiết null là sai.
Một thực tế đã bị chỉ trích dữ dội là chấp nhận giả thiết thay thế cho bất kỳ p-giá trị nào dưới 0,05 mà không có bằng chứng hỗ trợ khác. Mặc dù p-giá trị rất hữu ích trong việc đánh giá mức độ không tương thích của dữ liệu với một mô hình thống kê cụ thể, các yếu tố theo ngữ cảnh cũng phải được xem xét, chẳng hạn như: mục đích nghiên cứu, chất lượng của các phép đo, bằng chứng bên ngoài cho hiện tượng đang nghiên cứu và tính hợp lệ của các giả định làm cơ sở cho phân tích dữ liệu.
p-giá trị không phải là xác suất mà giả thiết null là đúng hoặc xác suất mà giả thiết thay thế là sai. p-giá trị có thể chỉ ra mức độ tương thích giữa tập dữ liệu và một giải thích giả thiết cụ thể (chẳng hạn như giả thiết null). Cụ thể, p-giá trị có thể được coi là xác suất tiên nghiệm để ít nhất cũng có được kết quả ít nhất là lớn nhất hay bé nhất như kết quả quan sát được, cho rằng giả thiết null là đúng. Không nên nhầm lẫn nó với xác suất hậu nghiệm rằng giả thiết null là đúng khi đã cho kết quả quan sát được. Điều này được thể hiện bằng công thức như sau:
Pr(quan sát | giả thiết) # Pr(giả thiết | quan sát)
Xác suất của việc quan sát thấy một kết quả khi biết rằng một giả thiết nào đó là đúng không tương đương với xác suất rằng giả thiết đó là đúng khi biết rằng kết quả đã nói trên được quan sát thấy. Trong trường hợp này, việc sử dụng p-giá trị như một “điểm số” cho giả thiết là phạm một lỗi logic nghiêm trọng khi nhầm lẫn khái niệm và vị trí giữa “giả thiết” và “quan sát”.
p-giá trị không phải là xác suất mà các kết quả quan sát được tạo ra chỉ bởi cơ hội ngẫu nhiên. p-giá trị được tính dưới giả định rằng một mô hình nhất định (thường là giả thiết null) là đúng. Điều này có nghĩa là p-giá trị là một tuyên bố về mối quan hệ của dữ liệu với giả thiết đó.
Mức ý nghĩa 0,05 (mức α) chỉ là một quy ước, thường được sử dụng làm ranh giới giữa một p-giá trị có ý nghĩa thống kê và một p-giá trị không có ý nghĩa thống kê. Tuy nhiên, điều này không có nghĩa rằng có một lý do khoa học để xem xét kết quả ở các phía đối lập của bất kỳ ngưỡng nào (khác với 0,05) là khác nhau về chất.
p-giá trị không cho biết kích thước hoặc tầm quan trọng của kết quả quan sát được. Một p-giá trị nhỏ có thể được quan sát cho một kết quả hoàn toàn không có ý nghĩa hoặc có giá trị quan trọng. Trong thực tế, nếu cỡ mẫu càng lớn thì kết quả tối thiểu cần thiết để tạo ra p-giá trị có ý nghĩa thống kê càng nhỏ.
|
Tài liệu trích dẫn 1. Andrew Rukhin et al., A Statistical Test Suite for Random and Pseudorandom Number Generators for Cryptographic Applications, NIST Special Publication 800-22 Revision 1a, April 2010. 2. William Palin Elderton, Tables for Testing the Goodness of Fit of Theory to Observation, Biometrika Trust, 1 (2), 1902, pp. 155–163. 3. Karl Pearson, On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling, Journal The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science, Series 5, Volume 50, 1900 - Issue 302, pp. 157–175. 4. Bhaskar Bhattacharya, DeSale Habtzghi, Median of the p-value under the alternative hypothesis, The American Statistician, 56 (3) 2002, pp. 202–206. 5. H.M.J. Hung, R.T. O'Neill, P. Bauer, K. Kohne, The behavior of the p-value when the alternative hypothesis is true", Biometrics, 53 (1) 1997, pp. 11–22. |
TS. Trần Duy Lai

16:00 | 17/03/2020

09:00 | 18/10/2019

17:00 | 13/02/2020

16:00 | 09/08/2024
Hiện nay, lĩnh vực thương mại điện tử đang trở nên phổ biến và phát triển mạnh mẽ, phục vụ nhu cầu mua sắm, trao đổi hàng hóa và dịch vụ cho hàng tỉ người dùng trên toàn cầu thông qua phương tiện điện tử và Internet. Những thách thức chính mà thương mại điện tử phải đối mặt hiện nay đó là các hình thức lừa đảo qua mạng và đánh cắp thông tin người dùng. Bài báo này trình bày những thách thức, yêu cầu đặt ra và những giải pháp an toàn cơ bản cho hệ thống thương mại điện tử hiện nay.

13:00 | 30/07/2024
Trong thế giới số hiện nay, việc nhận thức về cách các công ty thu thập và sử dụng dữ liệu của người dùng trở nên quan trọng hơn bao giờ hết. Nếu dữ liệu cá nhân rơi vào tay kẻ xấu, người dùng có thể trở thành nạn nhân của việc gian lận và bị đánh cắp danh tính. Dưới đây là năm lời khuyên để bảo vệ quyền riêng tư dữ liệu cho người dùng.

10:00 | 03/10/2023
Với sự gia tăng nhanh chóng của các mối đe dọa mạng tinh vi, các tổ chức ngày nay đang phải đối mặt với những thách thức lớn trong việc ngăn chặn và giảm thiểu các cuộc tấn công mạng. Để chống lại điều này, việc chia sẻ và phân tích thông tin tình báo về mối đe dọa vì thế càng trở nên mang tính cấp thiết và quan trọng. Nền tảng chia sẻ thông tin phần mềm độc hại (MISP) chính là một khuôn khổ nổi bật nhằm tạo điều kiện trao đổi thông tin tình báo về mối đe dọa giữa các tổ chức và cộng đồng an ninh mạng. Bài viết này cung cấp đánh giá cơ bản về nền tảng MISP, thảo luận về kiến trúc, các tính năng chia sẻ mối đe dọa cũng như những triển vọng của nó trong việc thúc đẩy phòng thủ an ninh mạng chủ động.

14:00 | 14/09/2023
NFT (Non-fungible token) là một sản phẩm của thời đại công nghệ mới và đang phát triển như vũ bão, ảnh hưởng sâu rộng đến nhiều lĩnh vực. Thị trường NFT bùng nổ mạnh mẽ vào năm 2021, tăng lên khoảng 22 tỷ USD và thu hút ước tính khoảng 280 nghìn người tham gia. Nhưng khi thị trường này phát triển, phạm vi hoạt động của tin tặc cũng tăng theo, đã ngày càng xuất hiện nhiều hơn các báo cáo về những vụ việc lừa đảo, giả mạo, gian lận và rửa tiền trong NFT. Bài báo sau sẽ giới thiệu đến độc giả tổng quan về NFT, các hành vi lừa đảo NFT và cách thức phòng tránh mối đe dọa này.

14:00 | 11/09/2024|Công nghệ PKI

11:00 | 03/09/2024|GP ATM

08:00 | 26/08/2024|GP ATM

10:00 | 19/08/2024|Tin tức sản phẩm

Trong cuộc đua 5G tại Việt Nam, Viettel đã vươn lên dẫn đầu khi trở thành nhà mạng đầu tiên chính thức tuyên bố khai trương mạng 5G. Trong khi đó, các nhà mạng khác cũng đang ráo riết chuẩn bị cho việc triển khai dịch vụ 5G, hứa hẹn một thị trường viễn thông sôi động và cạnh tranh trong thời gian tới.
09:00 | 29/10/2024

Nhằm trang bị cho người dân “vũ khí” chống lừa đảo trên không gian mạng, Cục An toàn thông tin (Bộ TT&TT) triển khai chiến dịch quốc gia với 5 nhóm kỹ năng thiết yếu, từ nhận biết dấu hiệu lừa đảo đến xử lý tình huống khi bị tấn công.
10:00 | 18/10/2024