Hiện nay, nhu cầu lưu trữ, sử dụng văn bản dưới dạng số ở trong nước nói chung và đề án chính phủ điện tử nói riêng đang là rất lớn. Vì vậy, việc tìm hiểu, nghiên cứu về các ứng dụng nhận dạng ký tự văn bản là rất cấp thiết. Trong lĩnh vực nhận dạng ký tự văn bản, việc ứng dụng trí tuệ nhân tạo đang ngày càng chứng minh được tính ưu việt với tốc độ nhanh và độ chính xác cao. Chúng tôi tập trung vào việc phân tích các thuật toán sử dụng, mô hình học sâu sử dụng thông qua việc khai thác thư viện Tesseract 4, qua đó đề xuất chương trình thử nghiệm trong nghiệp vụ cụ thể.
Một hệ thống nhận dạng văn bản được tổ chức bao gồm bốn thành phần [1]: Tiền xử lý, phân tích bố cục, nhận dạng văn bản và hậu xử lý như được thể hiện trong Hình 1a:
Trong đó, Tiền xử lý nhằm mục đích cải thiện chất lượng của hình ảnh. Phân tích bố cục cho phép xác định các đối tượng cơ bản trong tài liệu. Các đối tượng được xử lý ở bước này bao gồm chữ ký, từ, ký tự, … Nhận dạng văn bản phân loại các đối tượng được nhận dạng trong bước trước. Cuối cùng, quá trình hậu xử lý kiểm tra kết quả của bước phân loại trên cơ sở thông tin ngữ cảnh. Các mục tiếp theo sẽ lần lượt phân tích cụ thể từng thành phần của hệ thống nhận dạng văn bản.
Phân tích bố cục thực hiện việc phân đoạn hình ảnh tài liệu thành các vùng có nội dung đồng nhất (phân tích bố cục vật lý) và gán ý nghĩa và sắp xếp cho các vùng đó (phân tích bố cục logic). Các kĩ thuật phân tích bố cục vật lý có thể được biểu diễn Hình 1b.
.JPG)
Hình 1. Mô tả các thành phần của hệ thống nhận dạng văn bản (a) và phân loại các thuật toán phân tích bố cục vật lý (b)
Phương pháp từ dưới lên (bottom-up) thực hiện tìm, gán nhãn và phân tích các thành phần nhỏ lân cận nhau, sau đó tiến hành nhóm chúng lại và tìm đường bao quanh chúng tạo thành các vùng lớn hơn. Trong phương pháp từ trên xuống (top-down), một trang được phân đoạn từ các thành phần lớn hơn thành các thành phần con nhỏ hơn. Tesseract sử dụng phương pháp kết hợp của hai phương pháp này (hybrid) [8].
Tesseract là một công cụ nhận dạng ký tự quang học mã nguồn mở được phát triển tại HP trong khoảng từ năm 1984 đến năm 1994 [2]. Nó đã được sửa đổi và cải tiến vào năm 1995 với độ chính xác cao hơn. Cuối năm 2005, HP công bố mã nguồn mở Tesseract [4].
Tesseract OCR hoạt động theo từng bước theo sơ đồ khối được hiển thị trong Hình 4. Bước đầu tiên là Ngưỡng thích ứng, có chức năng chuyển đổi hình ảnh đầu vào thành hình ảnh nhị phân. Bước tiếp theo là phân tích thành phần liên thông, được sử dụng để trích xuất phác thảo ký tự. Phương pháp này rất hữu ích vì nó thực hiện OCR (nhận dạng văn bản) với văn bản màu trắng và nền đen. Sau đó, các phác thảo được chuyển đổi thành blob. Các blob này được tổ chức thành các dòng văn bản, các dòng và vùng được phân tích cho một số vùng cố định hoặc kích thước văn bản tương đương sử dụng phương pháp dựa trên phát hiện tabstop [5-7] (Hình 2a).
Kết thúc quá trình tìm dòng, phân tách các thành phần liên thông, Tesseract xây dựng một cơ chế nhận dạng từ, như Hình 2b [5].
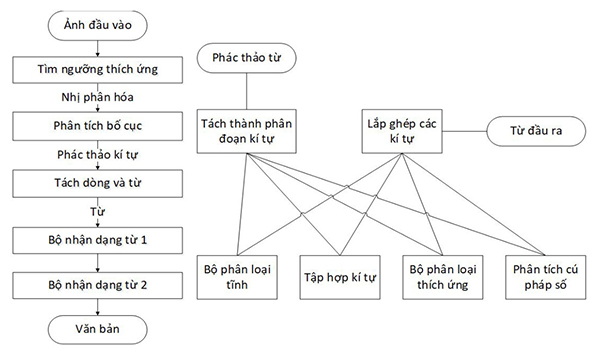
Hình 2. Kiến trúc của Tesseract OCR (a) và cơ chế nhận dạng từ của Tesseract (b)
Quá trình nhận dạng ký tự - là sử dụng các đặc trưng kết hợp với các phương pháp nhận dạng theo ngữ cảnh như: N-gram và nhận dạng từ - là phương pháp sử dụng xác xuất dự đoán các ký tự để đưa ra các từ hoàn chỉnh [11] [12].
Sau quá trình tách thành các phân đoạn kí tự, Tesseract tìm kiếm các tương đồng giữa các phân đoạn này với danh sách các từ, các số để đưa ra các từ. Tiếp theo, các từ được tách ra sẽ được đưa vào quá trình nhận dạng từ, toàn bộ từ sẽ được phân đoạn và được tách ra thành các kí tự đơn để nhận dạng các kí tự đơn qua hai bộ phân loại là: phân loại tĩnh (static character classifier) và phân loại thích ứng (adaptive character classifier) dựa trên các đặc trưng [8].
Sau khi kết thúc quá trình nhận tách và nhận dạng các kí tự đơn, một danh sách các kí tự lựa chọn được đưa ra, vấn đề tiếp theo là giải quyết sự mơ hồ (ambiguity) này để chọn ra lựa chọn tốt nhất cho từ. Hình 3 thể hiện việc chọn ra một đồ thị các kí tự tạo nên một từ [10] [11].
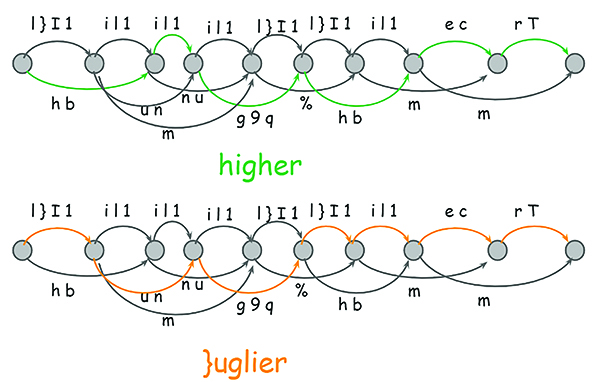
Hình 3. Minh họa việc lựa chọn đồ thị các kí tự để tạo thành một từ
Đây là quy trình xử lí nhận dạng kí tự của Tesseract được triển khai trên C++ từ phiên bản 3 trở xuống. Phiên bản Tesseract 4 mở rộng thêm mô-đun sử dụng những ưu điểm của kĩ thuật học sâu để nhận dạng kí tự quang học.
Ý tưởng chính của việc nhận dạng kí tự quang học sử dụng mạng học sâu là kết hợp các đặc trưng dạng chuỗi được trích xuất từ mạng CNN (convolution neutral network) [15] vào mạng xử lí đầu vào theo dạng chuỗi thời gian như là RNN (recurrent neutral network) [13]. Để đào tạo mô hình mạng này với nhận dạng kí tự, hàm mất mát được sử dụng là CTC (connectionist temporal classification) [14], như Hình 4.
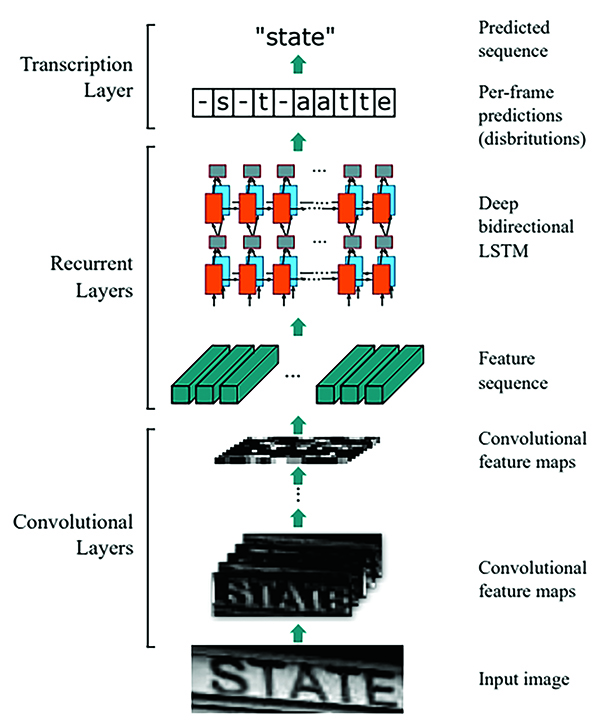
Hình 4. Cấu trúc mô hình mạng Deep Learning trong nhiệm vụ OCR
Mô hình (Hình 4) sử dụng mạng học sâu cho nhận dạng kí tự quang học gồm ba thành phần: lớp tích chập (CNN) sử dụng các cửa sổ trượt trên hình ảnh để trích xuất một chuỗi tính năng từ hình ảnh đầu vào; lớp hồi quy (RNN), dự đoán phân phối nhãn cho mỗi khung; lớp phiên mã, dịch các dự đoán trên mỗi khung thành chuỗi nhãn cuối cùng (sử dụng CTC).
Quá trình đào tạo một mô hình nhận dạng văn bản được thực hiện mô hình hóa thành các bước như Hình 5.
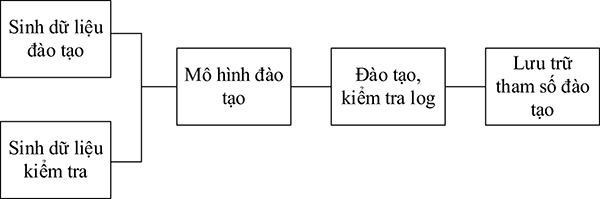
Hình 5. Sơ đồ khối quá trình đào tạo
Quá trình sinh dữ liệu đào tạo và sinh dữ liệu kiểm tra nhận đầu vào là văn bản dạng ký tự số và đầu ra là ảnh của văn bản đó, sau đó tất cả các ảnh và văn bản nhãn này được lưu trong tệp nén có đuôi .lstmf;
Tùy thuộc vào các phương thức đào tạo mà mô hình đào tạo được sửa, thay đổi, hoặc xây dựng lại từ đầu;
Trong quá trình đào tạo, phải kiểm soát tỉ lệ lỗi, tỉ lệ bỏ sót, điều chỉnh các tham số đào tạo. Bên cạnh đó, các tệp có đuôi checkpoint được sinh ra để lưu lại trọng số của mô hình tại các bước nhất định;
Cuối cùng, lưu trữ tham số bằng cách nén tệp có đuôi checkpoint tại bước cuối hoặc một bước nào đó, với các tệp liên quan thành tệp có đuôi .traineddata.
Tesseract cung cấp ba lựa chọn cho quá trình đào tạo để phù hợp với các mục đích và điều kiện khác nhau:
Fine tune: Mô hình đào tạo giữ nguyên bộ trọng số cho trước để đào tạo với dữ liệu khác.
Cut off the top layer: Mô hình đào tạo được xây dựng bằng cách cắt lớp trên cùng (hoặc một số lớp tùy ý) khỏi một mạng đã được đào tạo và đào tạo lại lớp trên cùng mới bằng cách sử dụng dữ liệu mới. Nếu Fine tune không hoạt động, thì hình thức này được ưu tiên sử dụng. Cắt bỏ lớp trên cùng vẫn có thể đào tạo một ngôn ngữ hoàn toàn mới.
Retrain from scratch: Mô hình đào tạo được xây dựng lại từ đầu, và được đào tạo với dữ liệu mới. Đây là một lựa chọn khó khăn, đòi hỏi phải có một bộ huấn luyện rất đặc trưng và đủ lớn cho vấn đề. Nếu không, mạng thu được có khả năng thực sự tốt trên dữ liệu đào tạo, nhưng không phải trên dữ liệu thực tế.
Đối với ngôn ngữ tiếng Việt, chữ viết có dấu, nên đối với các kí tự có dấu sẽ được mã hóa, phân giải thành các kí tự La-tinh thông thường, chính quá trình này bắt buộc quá trình tạo các lớp kí tự phải thực hiện lại từ đầu. Điều này khiến việc đào tạo với tiếng Việt không thể thực hiện bằng Fine tune hay Cut off the top layer mà phải được đào tạo từ đầu (retrain from scratch).
Nhằm mục đích đánh giá hiệu quả nhận dạng tiếng việt sử dụng công cụ Tesseract với các văn bản thường cho các trường hợp có thể xảy ra. Các trường hợp này bao gồm: sử dụng đầu vào là một tệp danh sách các ảnh như pdf, tiff được render trực tiếp từ văn bản; sử dụng đầu vào là các ảnh từ máy scan và sử dụng đầu vào là các ảnh từ máy ảnh. Chúng tôi tiến hành xây dựng 3 bộ dữ liệu cho quá trình đánh giá, 3 bộ dữ liệu này được sinh từ một văn bản gốc là một tệp docx với 3 cách sinh ảnh khác nhau. Cụ thể như sau:
Task 1: sử dụng đầu vào được render từ văn bản;
Task 2: sử dụng đầu vào là các tệp ảnh từ việc scan;
Task 3: sử dụng đầu vào là các tệp ảnh từ việc chụp ảnh. Kết quả thu được như Bảng 1.
Bảng 1. Kết quả việc đánh giá sử dụng Tesseract trong các trường hợp
.JPG)
Kết quả có độ chính xác từ lớn hơn độ chính xác kí tự, chứng tỏ dữ liệu chứa các cụm kí tự mà quá trình nhận dạng bỏ qua, ví dụ như nhiều dấu chấm trên một dòng trong mục lục như Hình 6.

Hình 6. Minh họa các lỗi trong quá trình đánh giá
Nếu chỉ sử dụng Tesseract cho các ảnh thực thế, kết quả thu được có thể khác nhiều so với kết quả mong đợi. Vì vậy cần sử dụng thêm các chương trình xử lí ảnh như loại bỏ vùng tối, vùng lóa, nhiễu hay thậm trí là phục hồi lại góc chụp để thu được ảnh gần với ảnh lí tưởng cho đầu vào nhất.
Trong phần này, chúng tôi ứng dụng OCR cho việc nhận dạng văn bản tiếng Việt có định dạng đặc thù riêng. Văn bản có định dạng đặc thù riêng chúng tôi sử dụng là văn bản có định dạng chia làm 2 cột như định dạng bài báo này. Trên mỗi cột là một bảng gồm nhiều dòng và 2 cột bị loại bỏ phần “border”. Tại mỗi ô “cell” trong bảng có thể chứa các giá trị hoặc không.
Ứng dụng được xây dựng hướng tới mục tiêu phát hiện các sai khác về mặt in ấn trong văn bản có định dạng đặc thù riêng như mô tả. Cụ thể, ứng dụng thực hiện so khớp các kí tự có được khi thực hiện quá trình OCR cho hai ảnh. Trong đó, một ảnh có được từ thực tế cần tìm lỗi in ấn; một ảnh có được bằng việc kết xuất trực tiếp từ văn bản gốc thông qua phần mềm kết xuất.
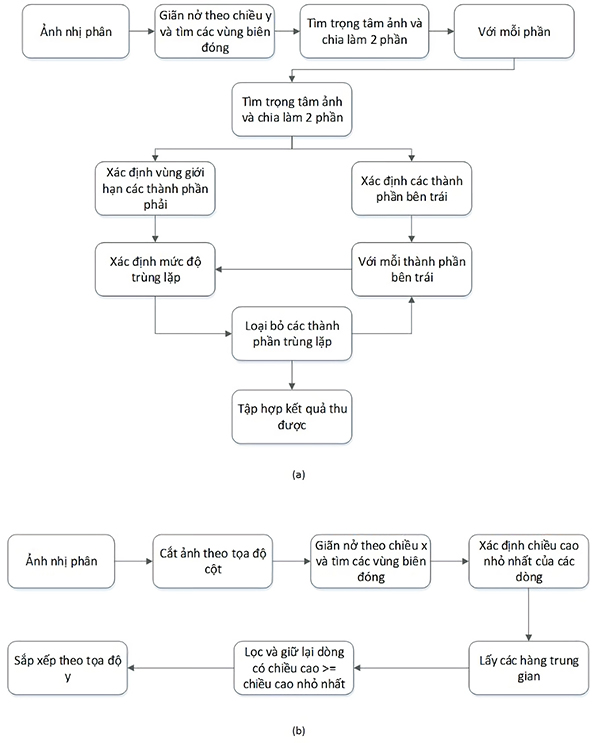
Đối với các văn bản có định dạng đặc thù riêng, nên nhận dạng ký tự trong nguyên một trang thì kết quả quá trình nhận dạng có thể sẽ không đạt hiệu quả. Để giải quyết vấn đề này, chúng tôi đề xuất phương pháp phân tích cấu trúc văn bản này, nhằm làm tối ưu hóa quá trình nhận dạng và so khớp các văn bản. Cụ thể, các mô-đun phát hiện cột và dòng được thực hiện trước khi tiến hành nhận dạng văn bản như được thể hiện trong Hình 7.
Toàn bộ quá trình loại bỏ vùng tối, phát hiện vùng chữ, phát hiện cột và phát hiện dòng đều được thực hiện nhờ các thuật toán Morphology (xử lý hình thái học trong OpenCV). Các phép toán thường dung liên quan đến thuật toán này là phép giãn nở (Dilation) và phép toán co (Erosion). Ở đây, chúng tôi sử dụng phép giãn nở (Dilation) để mở rộng các kí tự chữ cái theo chiều dọc hay chiều ngang nhằm phát hiện các cột, các dòng.
Trong đó, thuật toán loại bỏ vùng tối (Hình 8a) và thuật toán xoay văn bản (Hình 8b) theo hướng yêu cầu.
Vì văn bản quét có vùng văn bản và các đốm nhiễu khác, để thuật toán tập trung vào phần văn bản, chúng tôi sử dụng thêm thuật toán tìm vùng chữ như Hình 9.
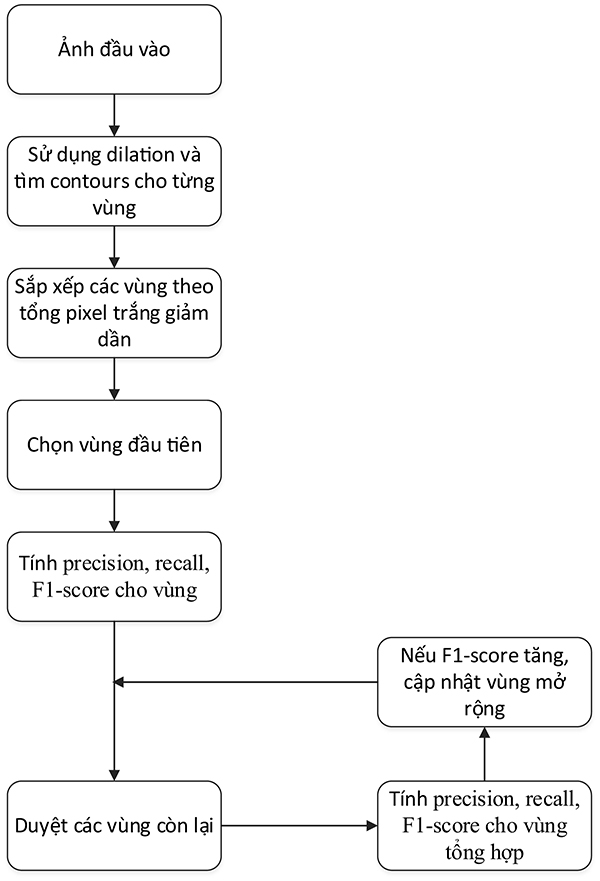
Thuật toán phát hiện cột, bằng cách sử dụng thuật toán Dilation, để giãn nở theo chiều dọc, đề thu được các cột như yêu cầu (Hình 10a) và thuật toán phát hiện dòng, bằng cách sử dụng thuật toán Dilation, để giãn nở theo chiều ngang, đề thu được các hàng như yêu cầu (Hình 10b).
Kết quả cuối cùng của các quá trình trên thu được là tọa độ các ô chứa chữ, quá trình tiếp theo là nhận dạng các kí tự trong các ô này. Quá trình này được thực hiện nhờ Tesseract, bằng cách gọi các API. Kết quả cuối cũng sẽ thu được các cặp (phần mã, phần rõ). Quá trình hậu xử lý kết quả nhằm ghép các dòng đôi trong cột bản rõ được thực hiện.
Kết quả đánh giá được thực hiện trên một tập văn bản có định dạng đặc thù riêng như mô tả, với 20 trang và phần mã là các kí tự số. Các bước thực hiện đánh giá trong phần này được thực hiện tương tự như Task 2 (ở trên). Dữ liệu đầu vào là 20 ảnh được scan từ máy scan, kết quả thu được như Bảng 2.
.jpg)
Hình 7. Quá trình thực hiện nhận dạng văn bản có định dạng đặc thù riêng
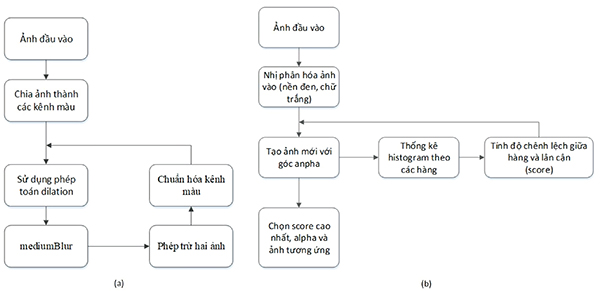
Hình 8. Minh họa thuật toán loại bỏ vùng tối (a) và minh họa thuật toán Deskew (b)
Hình 9. Minh họa thuật toán tìm vùng chữ
Hình 10. Minh họa thuật toán tìm cột (a) và minh họa thuật toán tìm dòng (b)
Bảng 2. Thể hiện kết quả thu được của thuật toán sử dụng nhận văn bản có định dạng đặc thù riêng

Từ việc tìm hiểu kiến trúc, các thành phần và cơ chế hoạt động của thư viện Tesseract, chúng tôi đã xây dựng một chương trình thử nghiệm sử dụng thư viện này kết hợp với các thư viện xử lí ảnh nhằm xây dựng thử nghiệm nhận dạng văn bản chữ in tiếng Việt có định dạng đặc thù riêng. Kết quả nhận dạng mở mức khá, chương trình có thể quét được toàn bộ vùng chữ tuy nhiên việc nhận dạng cho kết quả chỉ dừng ở mức 73,37%, do văn bản có chứa các kí tự đặc biệt, một số trường hợp bị lỗi dấu, dấu câu thì kết quả thấp hơn.
Từ các kết quả trên cho thấy khả năng phát triển hơn cho nhiệm vụ này bằng cách sử dụng thêm các quá trình xử lí ảnh ban đầu như, đào tạo lại mô hình với một số phông chữ chuyên dụng và sửa lỗi đầu ra.
|
TÀI LIỆU THAM KHẢO 1. Simone Marinai, “Introduction to Document Analysis and Recognition”, 2008 2. Ray Smith, “An overview of the Tesseract OCR Engine”, 2007 3. Chirag Patel, Atul Patel, Dharmendra Patel, “Optical Character Recognition by Open Source OCR Tool Tesseract: A Case Study”, 2012 4. 5. Ray Smith, Daria Antonova, Dar-Shyang Lee, “Adapting the Tesseract Open Source OCR Engine for Multilingual OCR”, 2009 6. Ray Smith, “Hybrid Page Layout Analysis via Tab-Stop Detection”, 2009 7. Faisal Shafait, Ray Smith, “Table detection in heterogeneous documents”, 2010 8. Mindy Bokser, “Omnidocument Technologies”, 1992 9. Simone Marinai, Hiromichi Fujisawa (Eds.) “Machine Learning in Document Analysis and Recognition”, 2008 10. Ray Smith, “Tutorial on Tesseract at DAS 2014”, 2014 11. Ray Smith, “Tutorial on Tesseract at DAS 2016”, 2016 12. 13. 14. Alex Graves, Santiago Fern´andez, Faustino Gomez, J¨urgen Schmidhuber “Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks”, 2006 |
ThS. Phạm Văn Lực, KS. Phạm Đức Hùng (Viện Khoa học - Công nghệ mật mã)

17:00 | 18/12/2023

08:00 | 04/12/2020

14:00 | 16/12/2022
14:00 | 20/01/2021

11:00 | 09/04/2021

12:00 | 18/05/2022

10:00 | 30/10/2024
Cục An toàn thông tin vừa phát đi cảnh báo về chiêu trò lừa đảo mới mạo danh cơ quan an sinh xã hội, dụ người dân nhận tiền hỗ trợ, trợ cấp... Tuy nhiên, đằng sau những lời "có cánh" lại là cái bẫy tinh vi nhằm chiếm đoạt tài sản.

10:00 | 22/04/2024
Những ngày gần đây, liên tục các kênh YouTube với lượng người theo dõi lớn như Mixigaming với 7,32 triệu người theo dõi của streamer nổi tiếng Phùng Thanh Độ (Độ Mixi) hay Quang Linh Vlogs - Cuộc sống ở Châu Phi với 3,83 triệu người theo dõi của YouTuber Quang Linh đã bị tin tặc tấn công và chiếm quyền kiểm soát.

09:00 | 08/03/2024
Từ lâu, botnet là một trong những mối đe dọa lớn nhất đối với an ninh mạng, nó đã gây ra nhiều thiệt hại cho các tổ chức và doanh nghiệp trên toàn thế giới. Bài báo sẽ giới thiệu tới độc giả một số kỹ thuật phát hiện botnet bằng Honeynet và tính hiệu quả của chúng, đồng thời đề xuất một số hướng phát triển trong tương lai để nâng cao khả năng phát hiện và ngăn chặn botnet bằng Honeynet.

09:00 | 17/11/2023
Theo Cục An toàn thông tin (Bộ TT&TT), hiện nay có 24 hình thức lừa đảo qua mạng phổ biến mà các đối tượng lừa đảo nhắm vào người dân. Để tránh trở thành nạn nhân, người dân cần nắm bắt, tuyên truyền cho người thân, bạn bè, đồng nghiệp của mình.

14:00 | 11/09/2024|Công nghệ PKI

11:00 | 03/09/2024|GP ATM

08:00 | 26/08/2024|GP ATM

10:00 | 19/08/2024|Tin tức sản phẩm
Trong thời đại ngày nay, cùng với sự phát triển của khoa học kỹ thuật có ngày càng nhiều những cuộc tấn công vào phần cứng và gây ra nhiều hậu quả nghiêm trọng. So với các loại tấn công khác, tấn công qua kênh kề đang được nghiên cứu do khả năng khôi phục lại khóa bí mật trong khi hệ thống vẫn hoạt động bình thường mà không hề làm thay đổi phần cứng. Bài báo này sẽ trình bày một cách sơ lược về những kết quả cuộc tấn công kênh kề lên mã hóa RSA cài đặt trên điện thoại thông minh sử dụng hệ điều hành Android tại Viện Khoa học - Công nghệ mật mã. Nhóm tác giả đã tấn công khôi phục được một phần khóa bí mật của mã hóa RSA cài đặt trên điện thoại thông minh và chứng minh khả năng rò rỉ thông tin qua kênh kề.
14:00 | 11/09/2024
Cục An toàn thông tin vừa phát đi cảnh báo về chiêu trò lừa đảo mới mạo danh cơ quan an sinh xã hội, dụ người dân nhận tiền hỗ trợ, trợ cấp... Tuy nhiên, đằng sau những lời "có cánh" lại là cái bẫy tinh vi nhằm chiếm đoạt tài sản.
10:00 | 30/10/2024